Route 53 Failover Implementation: Building High Availability for Café
Website
Project Overview
Implemented a fault-tolerant routing solution using Amazon Route 53 for
a café website. The goal was to ensure continuous service availability
by automatically failing over to a backup instance if the primary server
becomes unavailable.
Starting Environment:
-
CloudFormation-provisioned infrastructure with:
- Two EC2 instances with LAMP stack and café website
- Primary instance (CafeInstance1) in us-west-2a
- Secondary instance (CafeInstance2) in us-west-2b
-
Both instances pre-configured with:
- Full LAMP stack installation
- Identical café website deployment
- Public subnet placement for accessibility
Project Objectives:
- Implement automated health monitoring for the primary website
- Configure email-based alerting for downtime
- Set up DNS-based failover routing
- Ensure seamless user experience during failover events
Environment Validation
AWS Console Navigation:
-
Accessed AWS details:
- Clicked "Details" at top of page
- Selected "Show" for AWS credentials
- Copied down all instance information
-
Navigating to EC2:
- Opened AWS Management Console
- Used search bar to find and select "EC2"
- Selected "Instances" from left navigation pane
Instance Verification:
-
Retrieved essential information from CloudFormation outputs:
- IP addresses for both instances
- Primary and secondary website URLs
-
Performed initial testing:
- Accessed both café websites independently
- Verified server information displayed correct AZs
- Tested functionality by placing sample orders
- Confirmed order timestamps reflected server timezones
Route 53 Health Check Configuration
Console Navigation:
-
Accessed Route 53:
- Opened Services menu in AWS Console
- Searched for and selected "Route 53"
-
Ignored IAM-related warning messages (expected in lab environment)
- Selected "Health checks" from left navigation
Primary Endpoint Monitoring:
Name: Primary-Website-Health
Monitor Type: Endpoint
Endpoint Type: IP address
Path: /cafe
Check Interval: 10 seconds
Failure Threshold: 2
Alert System Setup:
- Created new SNS topic for notifications
- Configured email alerts for health check failures
- Added advanced monitoring settings for faster response
- Verified email subscription through confirmation link
DNS Configuration
Accessing Route 53 DNS Settings:
-
Navigation steps:
-
In Route 53 console, selected "Hosted zones" from left navigation
-
Located my unique domain name (format:
XXXXXX_XXXXXXXXXX.vocareum.training)
- Selected domain to view existing records
- Used "Create record" button for new entries
Hosted Zone Setup:
- Used provided domain: XXXXXX_XXXXXXXXXX.vocareum.training
- Preserved existing NS and SOA records
- Implemented failover routing strategy
Primary A Record:
Record Name: www
Type: A Record
TTL: 15 seconds
Routing Policy: Failover (Primary)
Target: CafeInstance1 IP
Health Check: Primary-Website-Health
Record ID: FailoverPrimary
Secondary A Record:
Record Name: www
Type: A Record
TTL: 15 seconds
Routing Policy: Failover (Secondary)
Target: CafeInstance2 IP
Health Check: None
Record ID: FailoverSecondary
Failover Testing Process
Console Navigation for Testing:
-
Stopping primary instance:
- Returned to EC2 console via Services menu
- Selected CafeInstance1 from instances list
- Used Instance state menu → Stop instance
- Confirmed action in Stop instance dialog
-
Monitoring failover:
- Returned to Route 53 via Services menu
- Selected Health checks from left navigation
- Found Primary-Website-Health check
- Accessed Monitoring tab in lower pane
Testing Steps:
-
Initial validation:
- Accessed website through Route 53 domain
- Confirmed traffic routing to primary instance
- Verified correct AZ display (us-west-2a)
-
Failover simulation:
- Initiated controlled shutdown of CafeInstance1
- Monitored health check status changes
- Observed time to "Unhealthy" status
- Received and verified email notification
-
Failover verification:
- Refreshed café website after status change
- Confirmed automatic switch to us-west-2b
- Validated full functionality on secondary instance
- Monitored DNS propagation time
Summary: Implementation Insights
-
10-second health check interval provides good balance of
responsiveness and reliability
-
15-second TTL enables quick failover but may need adjustment in
production
- DNS propagation requires patience during failover events
- SNS notifications provide reliable alerting for system health
- Secondary instance requires no health check configuration
-
Implementation provides automated failover with minimal service
disruption
This implementation demonstrates how Route 53 can provide robust failover
capabilities for web applications. The combination of health checks, DNS
routing, and notification systems creates a reliable high-availability
solution that can handle instance failures with minimal impact on service
availability.
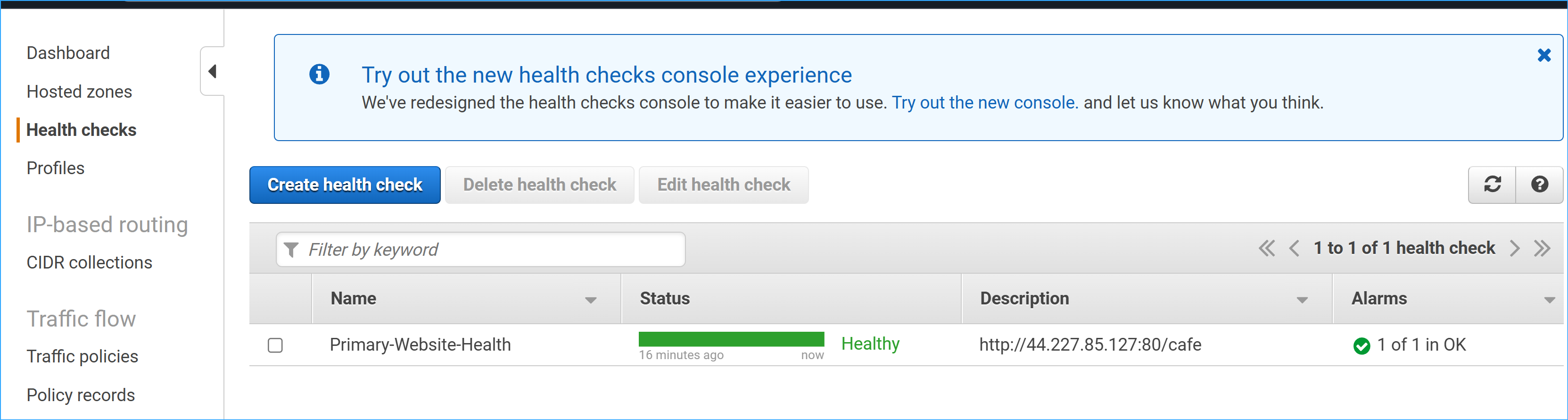 Primary Website Health Check Status
Primary Website Health Check Status
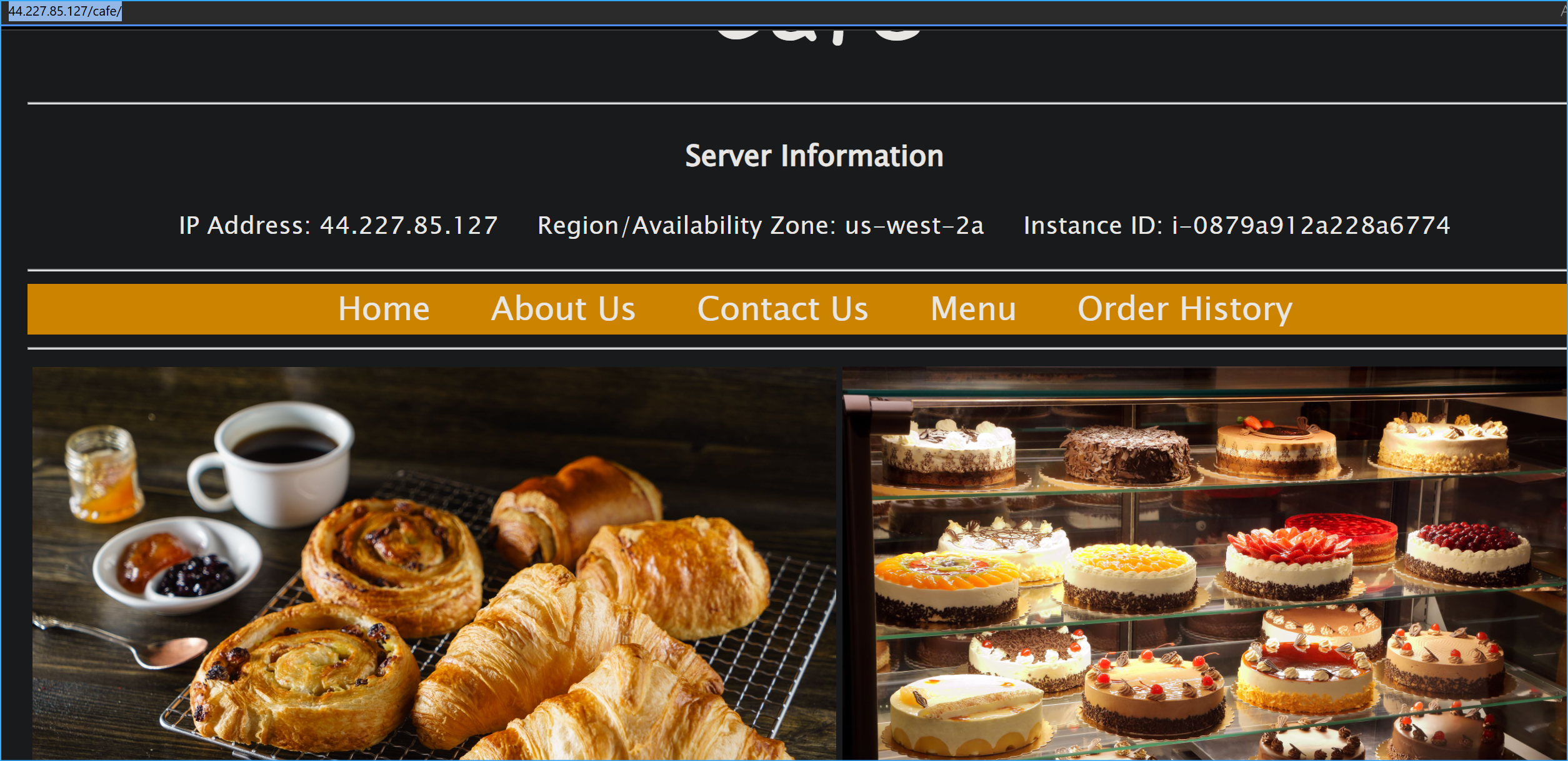 Cafe Site in AZ A
Cafe Site in AZ A
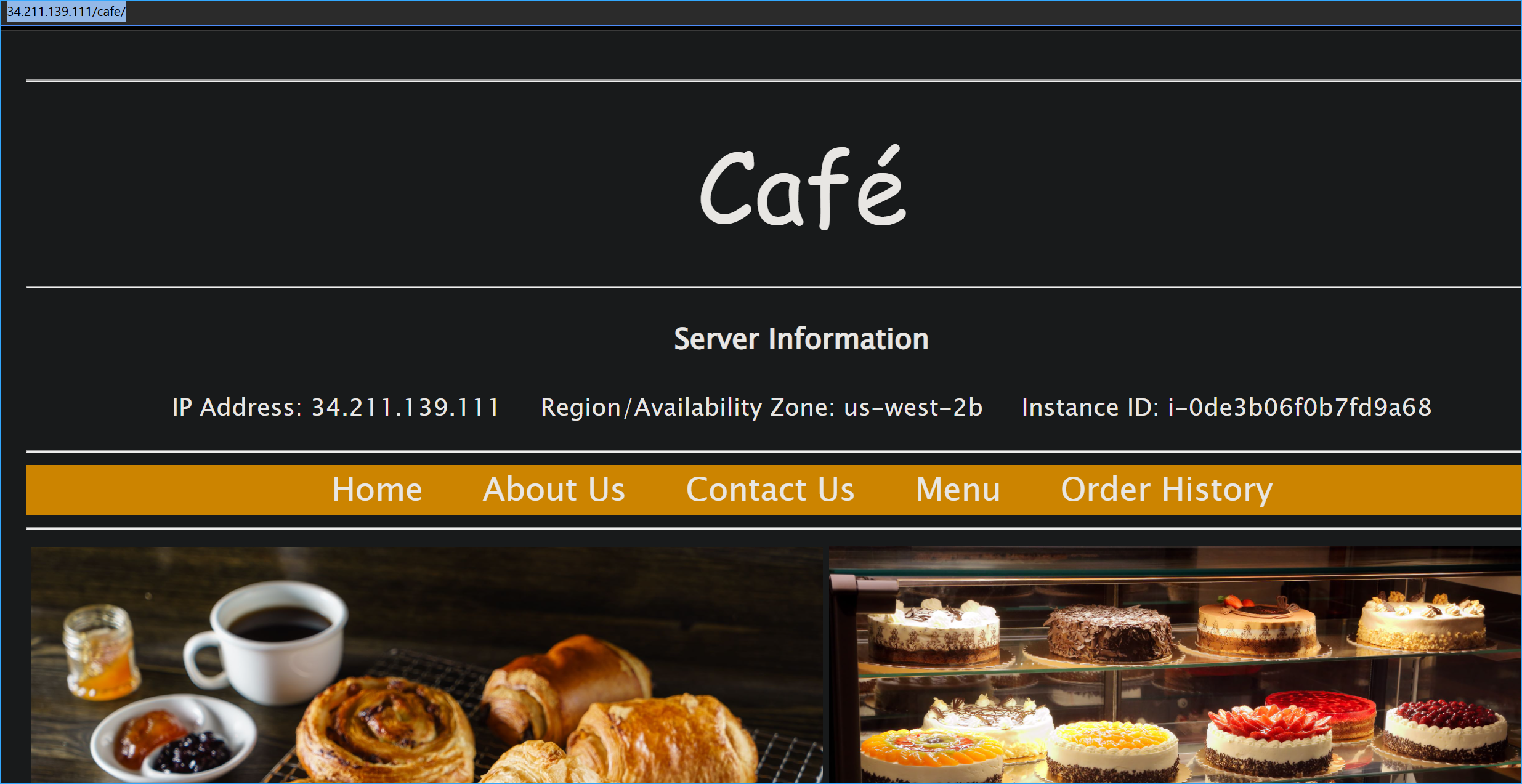 Cafe Site in AZ B
Cafe Site in AZ B
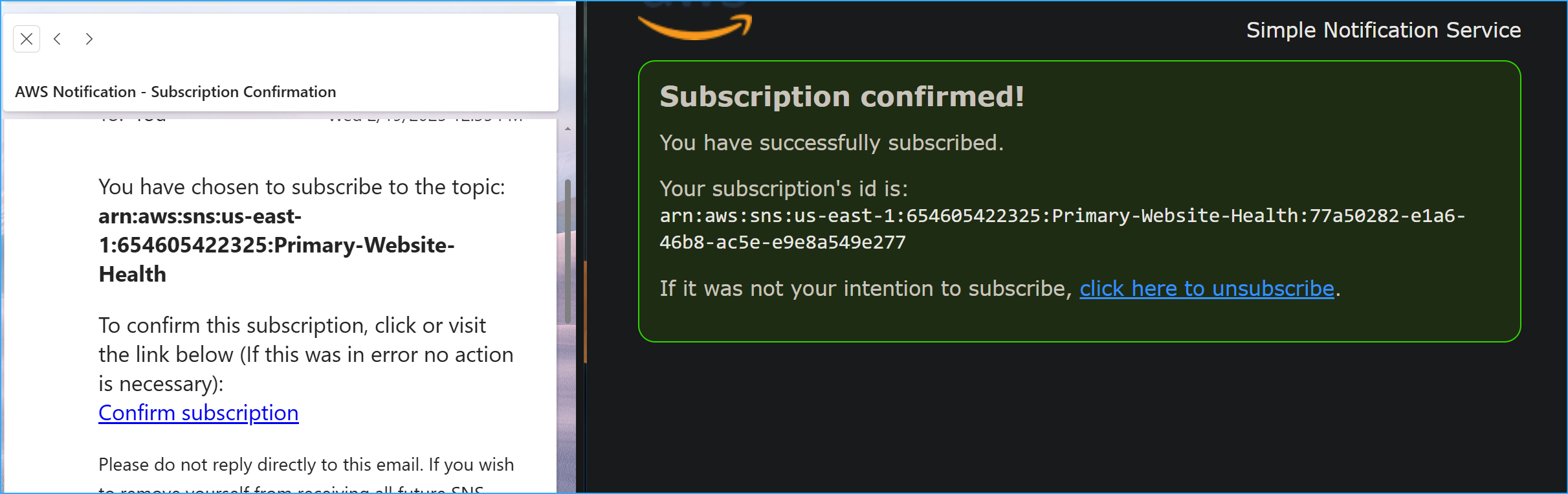 Subscription Confirmed
Subscription Confirmed
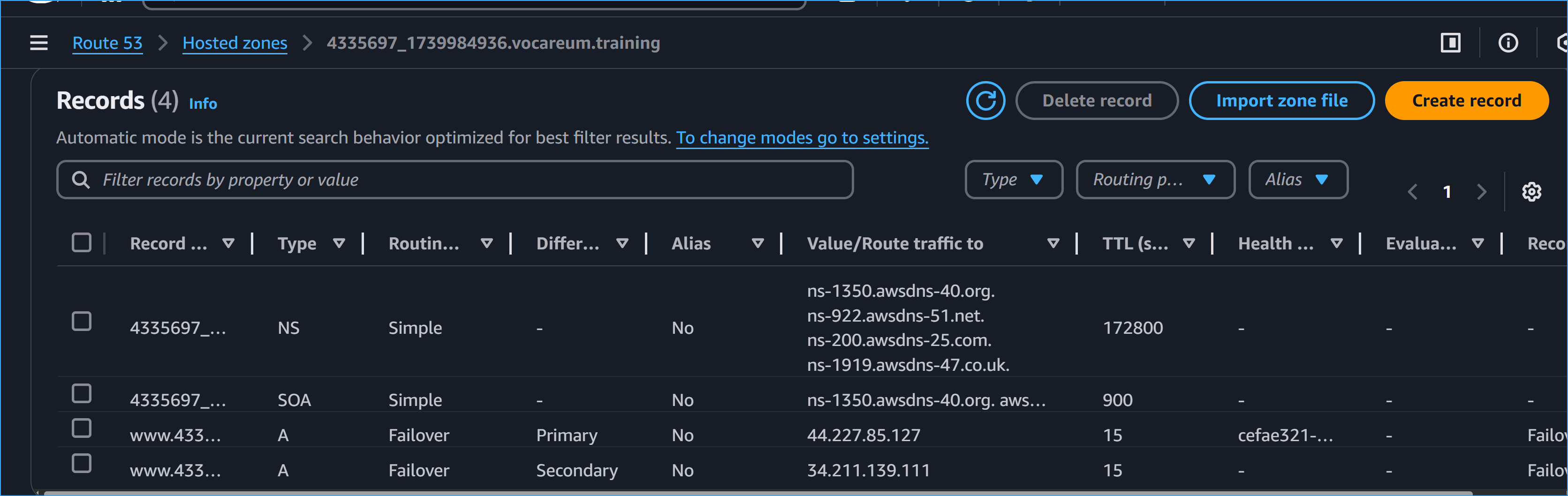 Created Record Types
Created Record Types
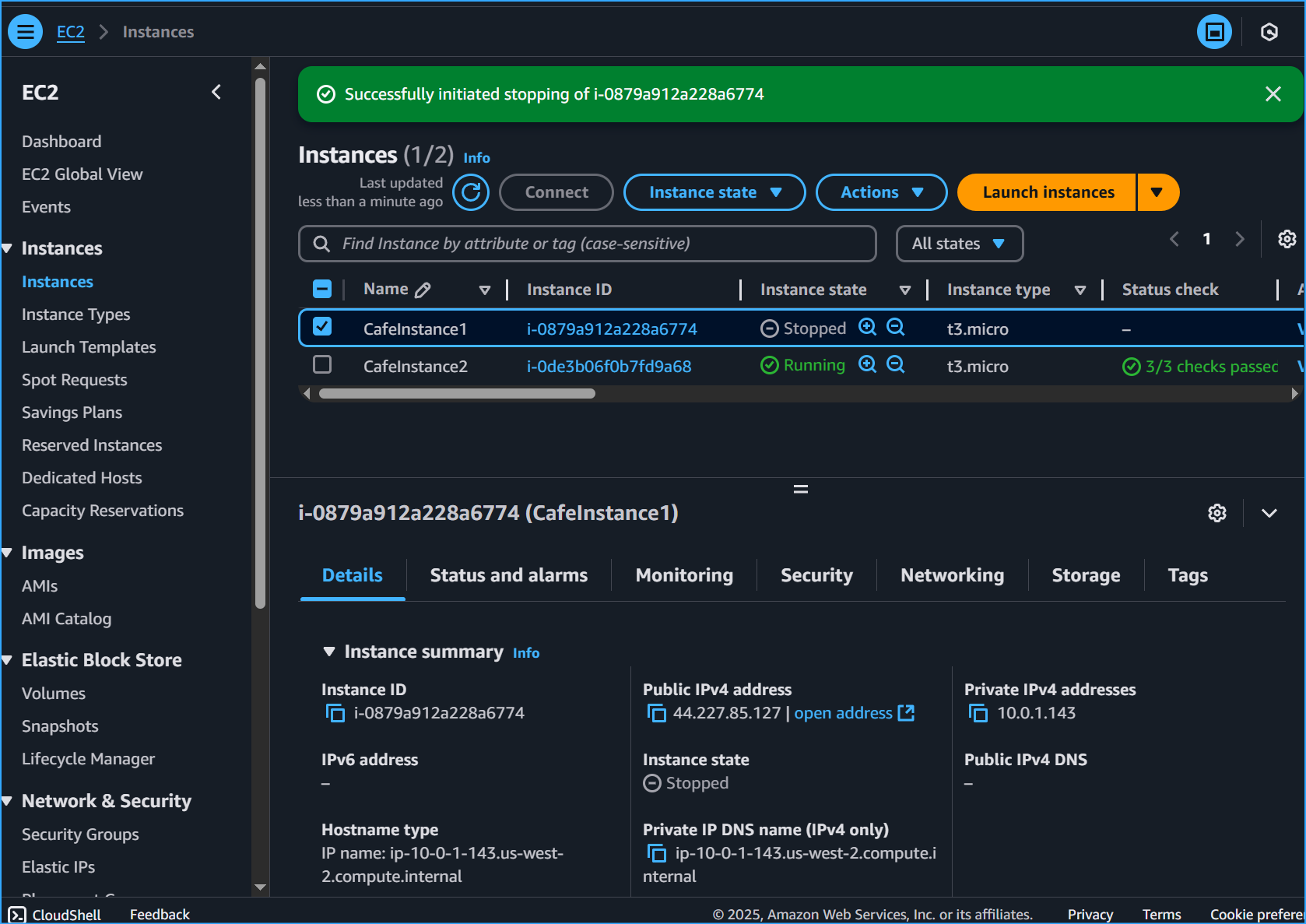 Stop Instance
Stop Instance
 Health Checks Failed When EC2 Instance Stopped
Health Checks Failed When EC2 Instance Stopped
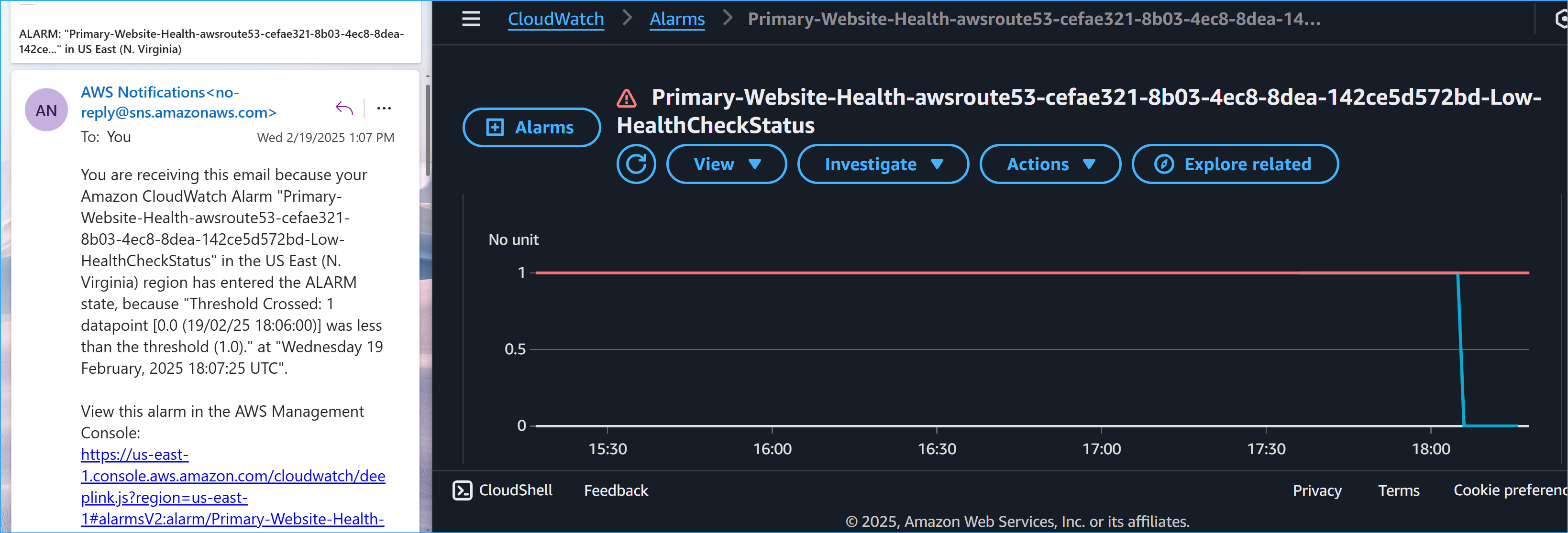 Cloud Watch Alarm SNS
Cloud Watch Alarm SNS
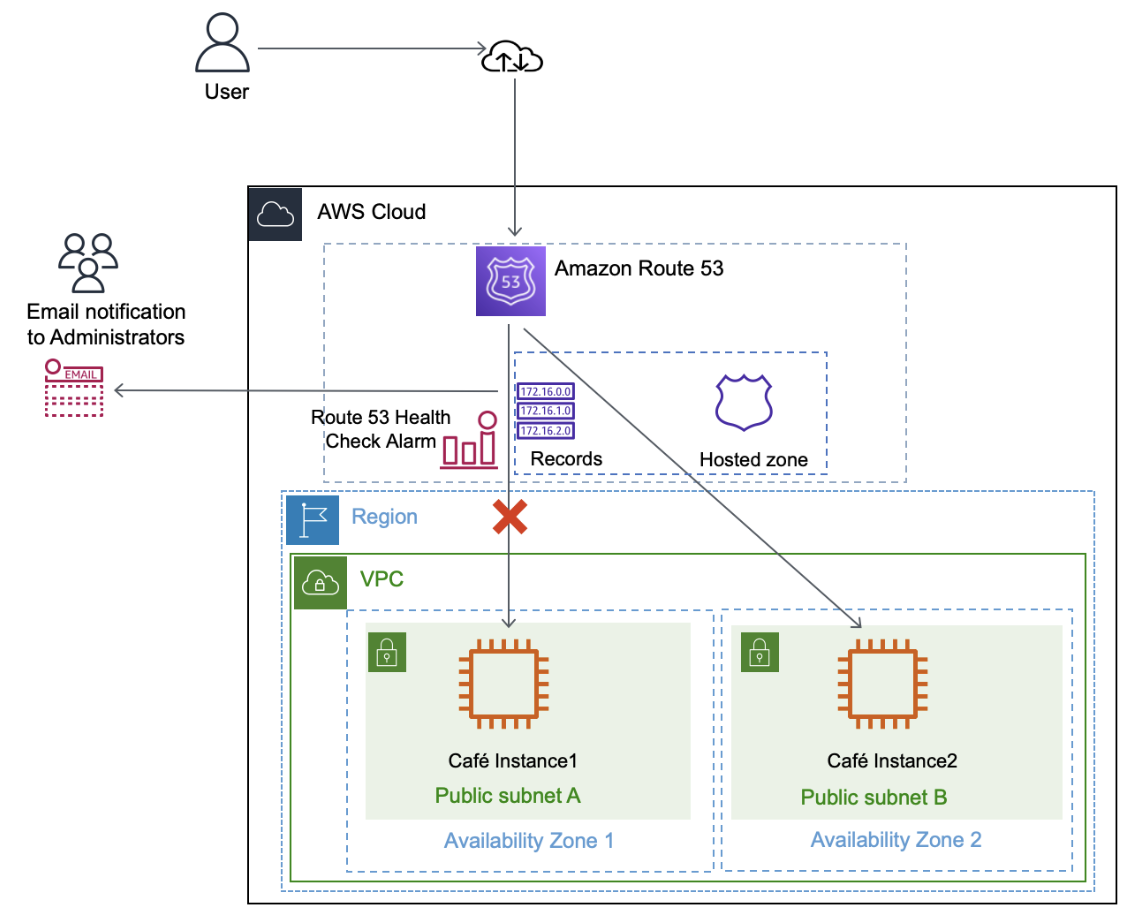 When Finished Will Look Like Following Architecture
When Finished Will Look Like Following Architecture